Research
My research is in topological data analysis and computational geometry, especially in settings motivated by machine learning. This page gives a compact overview of two threads of that work and points to papers that contain the full technical details.
Persistent Homology
The standard output of persistent homology is the persistence diagram. This diagram captures at what parameter values topological features appear and when they disappear, and thus, how persistent topological feature are within the data. However, we for each feature, we can also capture where these features appear in the data during their lifetime. The representatives of persistent homology generators provide a geometric visualization of where these holes are in the data.
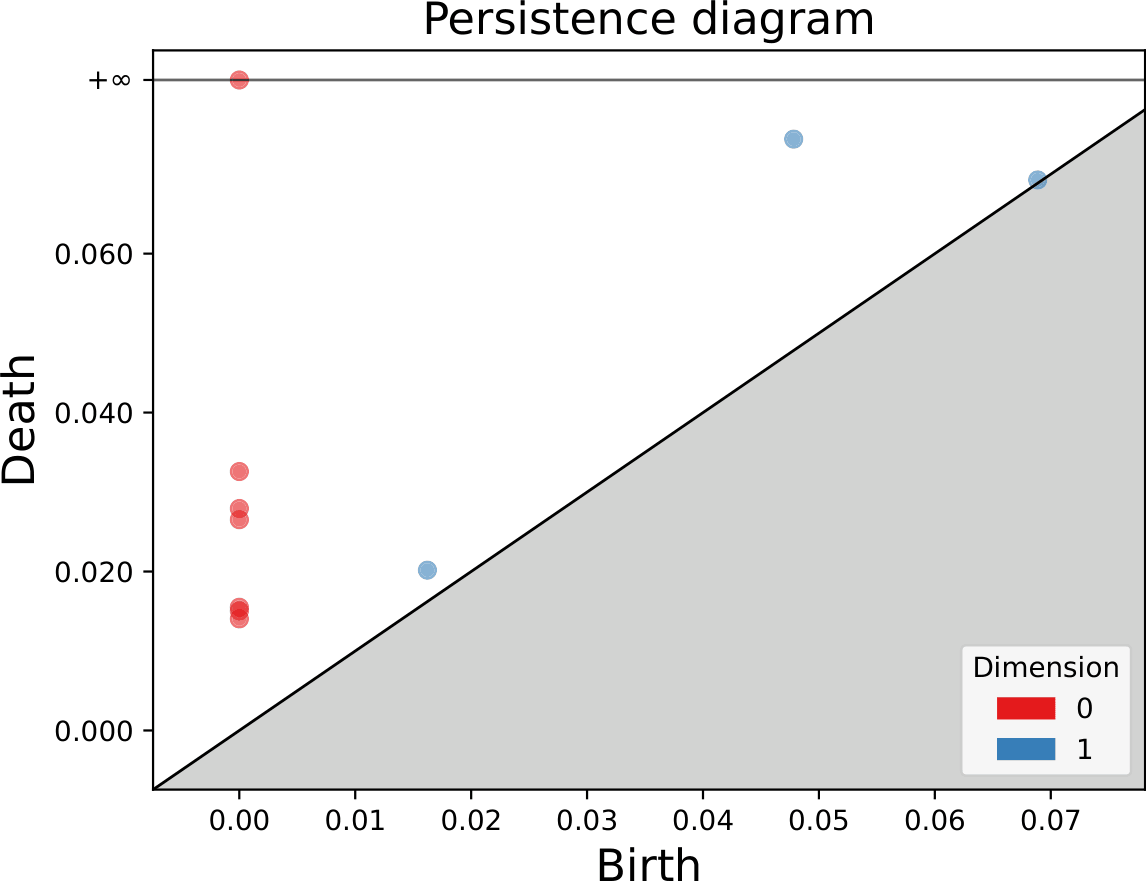
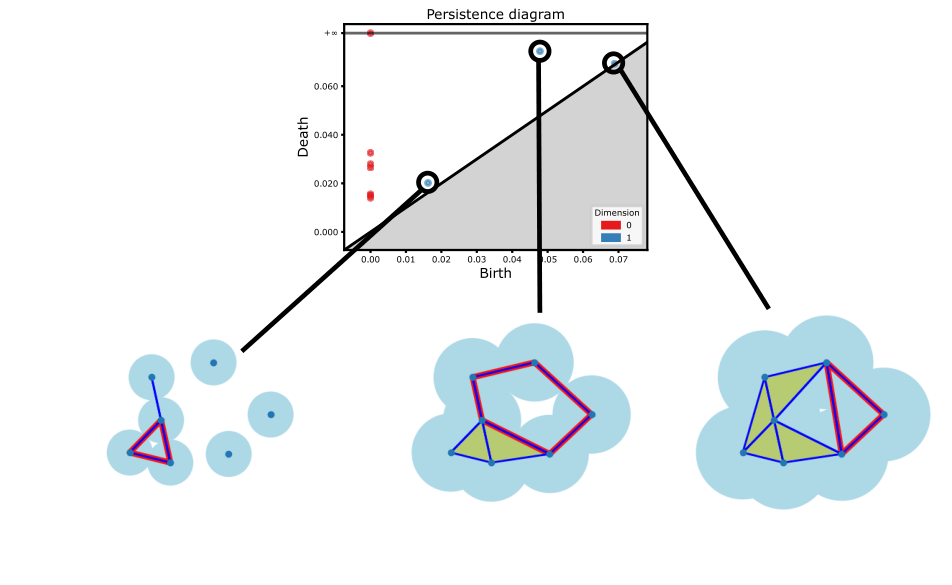
We introduce a meta algorithm for computing persistent homology generators when the high dimensional simplices dominate the filtration. It can be implemented in any preexisting software, utilizing the provided algorithms. Our method is experimentally shown to be over 200$\times$ faster than the standard algorithm for computing these representative cycles in PHAT.
Virk and Čufar independently devised this algorithm and implemented Ripserer for Vietoris–Rips complexes in Ripser.
Bregman Divergences
- “Fast Kd-Trees for the Kullback–Leibler Divergence and Other Decomposable Bregman Divergences” - P., Wagner
- “Bregman-Hausdorff divergence: strengthening the connections between computational geometry and machine learning” - P. Dal Poz Kouřimskà, Wagner
For machine learning tasks which utilize a loss function for training, the outputs of the model lie in a space dependent on the loss function. Thus, if we want to analyze the outputs of models, we should do so with tools which respect the geometry induced by said loss functions. This project focuses on the family of Bregman divergences. To motivate Bregman divergences, consider relative entropy.
Example In machine learning and information theory, a popular dissimilarity measurement between probability distributions is relative entropy, also known as the Kullback–Leibler (KL) divergence. We can write relative as a Bregman divergence.
\[\begin{align*} D_{KL}(x\|y) &=\sum_{i=1}^k x_i\log_2 \frac{x_i}{y_i}\\ &=-\sum_{i=1}^k x_i\log_2 \frac{1}{x_i} - \sum_{i=1}^{k}x_i\log_2\frac{1}{y_i}\\ &=-\text{entropy} - (-\text{cross entropy})\\ &= \text{cross entropy} - \text{entropy}\\ \end{align*}\]For classifiers, the cross entropy is minimized as a shortcut for minimizing the KL divergence. Thus, analytical tools for interpretting classifier models should respect the geometry induced by the KL divergence.
Other popular examples of Bregman divergences include:
- Squared Euclidean distance;
- Itakura–Saito divergence; Useful as a loss function for signal processing tasks
- Mahalanobis divergences; Often defined with covariance matrices from statistics
Bregman divergences are not metrics. Only the subfamily of Mahalanobis Bregman divergences can be symmetric, and Bregman divergences never satisfy the triangle inequality. Despite the lack of metric features, Bregman divergences permit a well-behaved geometry. Many geometric constructions have been extended to the Bregman setting, and thus we can use them to extend data analysis algorithms that rely on the geometry. Previously extended algorithms/data structures include:
- $k$-means clustering by Banerjee and collaborators
- Voronoi diagrams by Nielson, Piro, and Barlaud
- Ball trees by Cayton later improved by Nielson, Piro, and Barlaud
- Vantage point trees by Nielson, Piro, and Barlaud
We extend the Kd-tree beyond its usual Euclidean application for computing both exact and approximate $k$-nearest neighbours. For example, this can tell us what a classifier model may perceive to be similar to a misprediction, which allows for more careful training or restructuring of the model.
The Bregman Kd-tree can additionally quickly compute the Bregman—Hausdorff divergence, a measurement of divergence between sets of unpaired vectors. This concept is useful in generative models where generated data is not explicitly matched with training data.
Bregman Kd-trees are more efficient than other competing public portable implementations and are available at the BANN GitHub repository. The package is also installable with pip and can be found on PyPI.